Fetchers
What is a fetcher?
In DBnomics, data acquisition is done by fetchers, small programs that download data from provider infrastructures and convert it to a common data model and format.
There is one fetcher per data provider.
Here is a diagram that shows the main steps of a fetcher:
flowchart LR
provider@{ shape: cloud, label: "Data Provider<br/>(e.g. OECD)" }
subgraph fetcher["Fetcher"]
direction LR
download["Download"]
source_data[("Source<br/>data")]
convert["Convert"]
converted_data[("Converted<br/>data")]
end
style fetcher fill:#ffffff,stroke:#000000,stroke-dasharray: 3 3
download -->|download| provider
download -->|write| source_data
convert -->|read| source_data
convert -->|write| converted_dataThe source code of the fetchers is hosted in a GitLab group: https://git.nomics.world/dbnomics-fetchers. Each repository is dedicated to a fetcher, for example https://git.nomics.world/dbnomics-fetchers/insee-fetcher.
To write a new fetcher or maintain an existing one, see contributing.
Fetcher pipeline
The fetcher pipeline is the part of the DBnomics infrastructure that runs fetchers and makes their output available on the DBnomics website and Web API.
The source code of the fetcher pipeline is available in the dbnomics-fetcher-pipeline repository.
Fetcher pipelines are scheduled regularly (daily by default) in order to keep DBnomics data up to date.
flowchart LR
scheduler["GitLab scheduler"]
subgraph fetcher["Fetcher domain"]
direction LR
download["Download job"]
source_data[("Source data")]
convert["Convert job"]
converted_data[("Converted data")]
end
index["Index job"]
validate["Data validation job"]
deploy["Deploy job"]
style fetcher fill:#ffffff,stroke:#000000,stroke-dasharray: 6 4
scheduler --> download
download --> convert
convert --> index
convert --> validate
download -.->|push| source_data
convert -.->|push| converted_data
index --> deployDashboard
The dashboard shows the status of the latest pipeline executions for each fetcher.
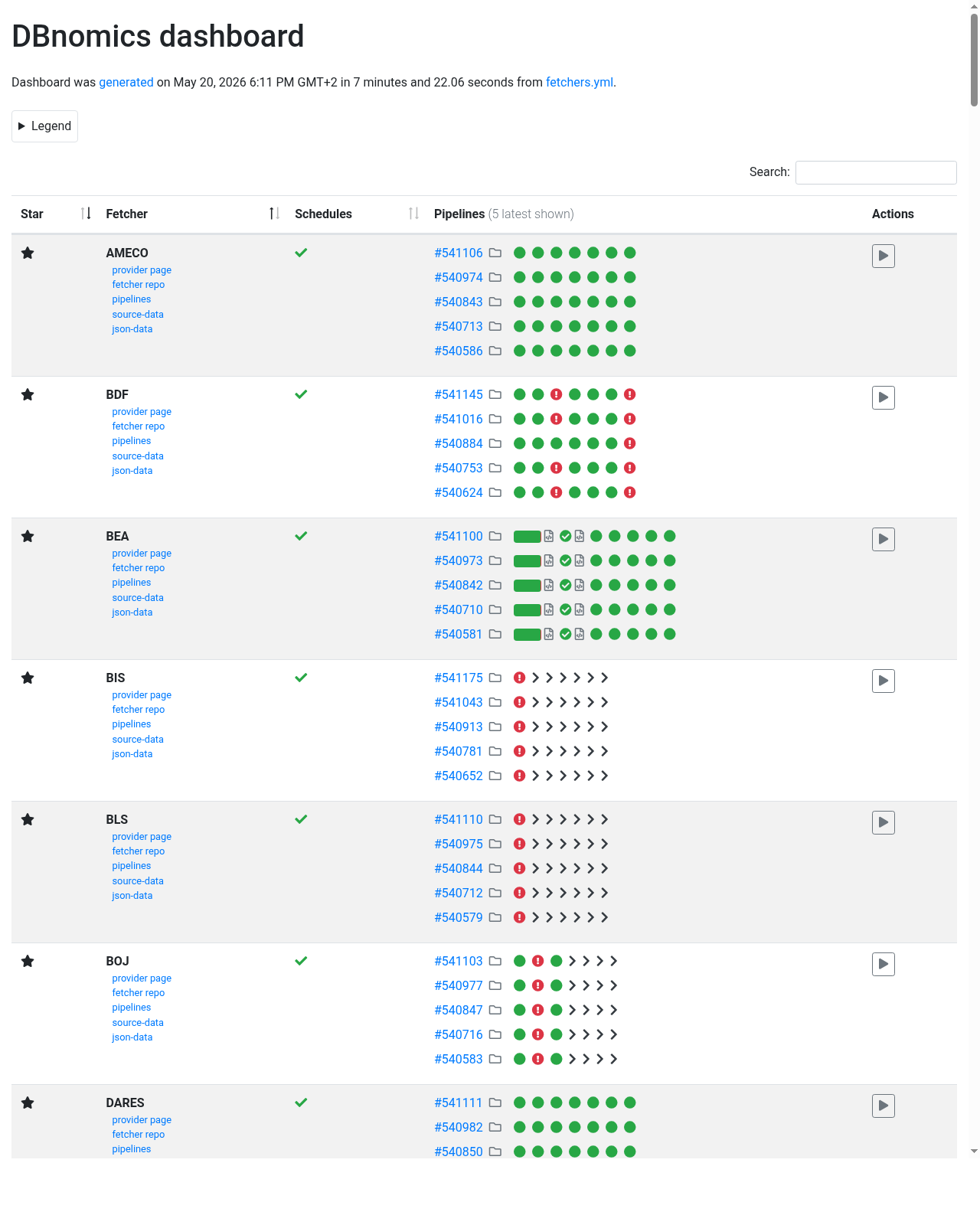
Its source code is available in the dbnomics-dashboard repository.